






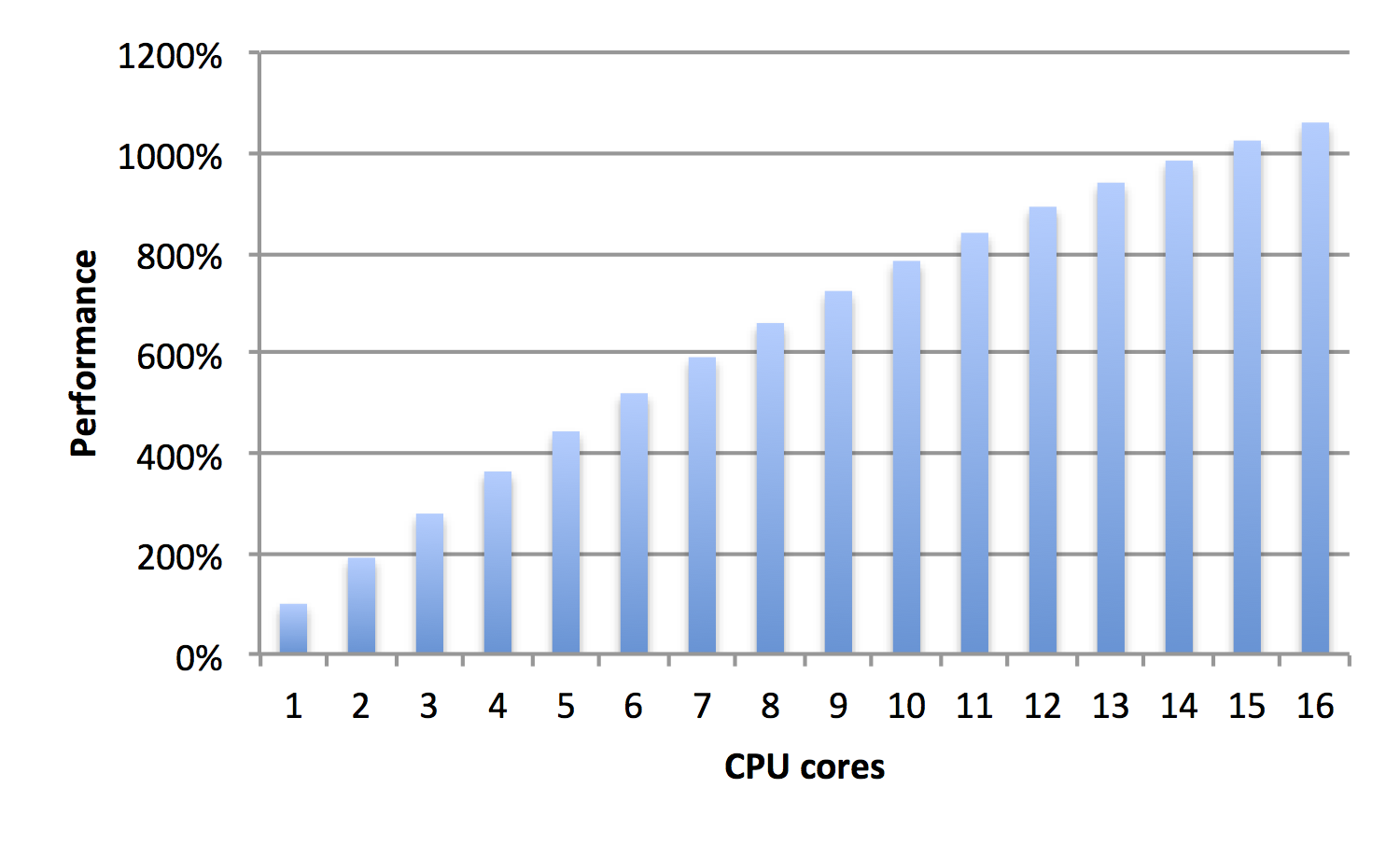
In the decade leading to 2001, Intel CPUs went from 33-MHz to 3-GHz, hundred-fold increase in speed. In the decade since, they’ve been stuck at 3-GHz. Instead of faster clock speeds, they’ve been getting more logic. Instead of one instruction per clock cycle, they now execute four (“superscalar”). Instead of one computation per instruction, they now do eight (“SIMD”). Instead of a single CPU on a chip, they now put four (“multi-core”).
However, desktop processors have been stuck at four cores for several years now. That’s because the software is lagging. Multi-threaded software goes up to about four cores, but past that point, it fails to get any benefit from additional cores. Worse, adding cores past four often makes software go slower.
This post talks about scaling code past the four-core limit. Instead of the graph above showing performance falling off after four cores, these techniques lead to a graph like the one below, with performance increasing as more cores are added.
The reason code fails to scale is that it’s written according to out-of-date principles based on “multi-tasking”. Multi-tasking was the problem of making a single core run multiple tasks. The core would switch quickly from one task to the next to make it appear they were all running at the same time, even though during any particular microsecond only one task was running at a time. We now call this “multi-threading”, where “threads” are lighter weight tasks.
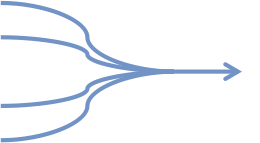
But we aren’t trying to make many tasks run on a single core. We are trying to split a single task across multiple cores. It’s the exact opposite problem. It only looks similar because in both cases we use “threads”. In every other aspect, the problems are opposite.
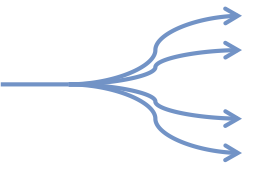
The biggest issue is synchronization. As your professors pounded into you, two threads/cores cannot modify the same piece of data at the same time, or it will be corrupted. Even if the chance of them doing the modification at the exactly the same time is rare, it always happens eventually. Computers do a billion computations per second, so if the chance is one in a billion, that means corruption happens about once per second.
The proscribed method for resolving this is a “lock”, where one thread stops and waits when another thread is modifying that piece of data. Since it’s rare for two threads to actually conflict in practice, it’s rare for a thread to actually wait.
There are multiple types of locks, like spinlocks, mutexes, critical sections, semaphores, and so on. Even among these classes there are many variations. What they all have in common is that when conflict occurs, they cause the thread to stop and wait.
It’s the waiting that is the problem. As more cores are added, the chance they’ll conflict and have to wait increases dramatically. Moreover, how they wait is a big problem.
In the Linux “pthread_mutex_t”, when code stops and waits, it does a system call to return back to the kernel. This is a good idea when there’s only one CPU core running multiple threads because of course, the current thread isn’t going to be able to make forward progress anyway until whichever thread owns the lock is allowed to proceed to release the lock.
But with multi-core, this becomes insanely bad. The cost of going into the kernel and going through the thread scheduling system is huge. It’s why software using “mutexes” gets slower as you add more cores, because this constant kernel traffic adds a lot of extra overhead.
In short, mutexes are good when many threads share a core, but bad when it’s a single thread per core.
What we want is synchronization that doesn’t cause a thread to stop and wait. The situation is a lot like traffic intersections, where multiple flows of automobiles must share a common resource. One technique is to use traffic lights to force one direction to stop and wait while the other proceeds. Another technique is the freeway, where an overpass is used to allow both directions to proceed at the same time without stopping.
What we therefore want is “freeway overpass” synchronization. Such techniques exist, though they can get very complicated.
The most basic technique exploits the fact that on modern CPUs, either reading or writing a number in memory is atomic. By this I mean that combining a read with a write can lead to corruption, but doing either a read or a write alone does not. In the past, reading a multibyte number could lead to corruption, because in the nanoseconds between reading the first byte of a number another core could write to the second byte. This can no longer happen.
Let’s exploit this fact with the packet counters on Linux. The network stack keeps track of packets/bytes received/transmitted, as well as counts of errors that occur. Multiple cores may be processing different packets at the same time. Therefore, they need to synchronize their updates to the packet counters. But, if they have to stop and wait during the synchronization, this will lead to an enormous packet loss.
The way they solve this is for each core to maintain its own packet counters. When you call “ifconfig” to read the packet counters and display them, that thread just sums up all the individual core’s counters into a single set of counters. Because that thread only reads the counters, and reads are atomic, no corruption is possible.
Well, some corruption is possible. Consider if the program wanted to report “average packet size”, which is calculated by “total bytes” divided by “total packets”. Reading a single integer is atomic, but reading both integers is not. Therefore, it’s possible that sometimes the thread will read “total bytes”, then another core updates the counters, then the thread reads “total packets” and does the calculation. This will lead to a slightly less average packet size than if these counters were properly synchronized. So this technique isn’t perfect, but depends on your requirements.
This is just one example. There are many other techniques for narrow cases where either traditional synchronization is not needed at all, or can mostly be avoided. Some terms to google along this line are the “ring buffer” and “read copy update (RCU)”.
When we say “atomic”, though, we don’t mean an individual read or write, but combining the two into a single, non-interuptable operation.
The x86 processor has an assembly language instruction called “lock”. It’s not really it’s own instruction, but instead modifies the following instruction to be atomic. When the normal “add” instruction reads data from memory, adds to it, then writes the data back, another core could modify that memory location in the meantime, causing corruption. The “lock add” instruction prevents this from happening, guaranteeing the entire addition to be atomic.
Think of this as a “hardware mutex” rather than the traditional “software mutex”, only that it causes code to stop and wait for 30 instruction cycles rather than 30,000. By the way, the cost is because this is done within the L3 or “last level” cache. On current Intel CPUs, that’s about 30 clock cycles.
The “lock” prefix works only on a few arithmetic instructions, and only one value at a time. To work with more than one value, you need to use the “cmpxchg16b” instruction. What you do is first read 16 bytes of data. Then you make all your changes you want on that 16 bytes. Then using “cmpxchg16b”, you attempt to write all the changes back again. If that memory was changed in the meantime, this instruction fails and sets a flag. That way, you know synchronization failed, data would have been corrupted, and that you must back up and try again.
It’s 16-bytes because that’s the size of two pointers. It allows you to modify two pointers atomically, or a pointer plus an integer. This feature is called “CAS2” or “compare-and-swap two numbers”, and is the basis for a lot the “lock-free” stuff described below.
Intel’s new “Haswell” processor shipping in mid-2013 extends this model to “cmpxchg64b” or “cmpxchg128b”, where the regions of memory do not have to be next to each other. This feature is called “transactional memory”. This will make good, fast, scalable synchronization must easier in the future.
You don’t want to mess around with assembly language, especially since you want your code to run on both x86 and ARM. Therefore, compilers let you access these instructions with built-in functions. On gcc, example functions are __sync_fetch_and_add() and __sync_bool_compare_and_swap(). They work just as well on x86 as ARM. Microsoft has similar intrinsics for their compilers.
The above atomics act on one thing at a time. In practice, you need something more complex. For example, you might have 100 CPU cores trying to work off the same hash table, inserting things, removing things, and even resizing the entire table, all at the same time, all without requiring a core to stop and wait for another to finish.
The general term this goes under is “lock-free”. You don’t have to write hash-tables, linked-list, and other data structures yourself. Instead, you simply use libraries created by other people.
You can also link to large subsystems that incorporate lock-free inside. A good example are “heaps” or “malloc()”. The standard Microsoft heap has a global mutex that really saps performance on multi-core code. You can replace it with a lock-free heap simply by linking to another library. And such things tend to be cross platform.
You should be very afraid of doing this yourself, unless you are willing to study the problem in its entirety. It’s like crypto: people tend to make the same naïve mistakes. One example is the “ABA” problem. When doing a “compare-and-swap” like cmpxchg instruction mentioned above, sometimes the value changes, then changes back again. Thus, you think nothing else has changed, by it has. Another example is the “weak/strong memory model” problem: your lock-free code might work on x86 but fail on ARM. If you get the desire to write your own lock-free algorithms, google these issues, otherwise, they will bite you.
While synchronization is the biggest issue with thread scalability, there are other concerns as well.
When you go multi-core, you have to divide your application across multiple cores. There are two fundamental ways of doing this: pipelining and worker-threads. In the pipeline model, each thread does a different task, then hands off the task to the next thread in the pipeline. In the worker model, each thread carries out the same task. Of course, you can combine the two models, where you might have equal worker threads at a stage in the pipeline.
There are tradeoffs for each approach. In the pipeline approach, there is a lot of synchronization overhead as you pass the job from one thread to the next. In the worker thread, anything that is shared among all the threads becomes a synchronization bottleneck.
Thus, when there is a shared resource, you want to split that off as a stage in a pipeline. When threads can work independently without sharing something, you want peer worker threads.
Consider a multi-core IDS (intrusion detection system) like Snort as an example. The first stage is pulling packets from the network adapter to be analyzed. This is a shared resource among all the threads, and hence, a synchronization bottleneck. You might therefore want to split this out as a pipeline stage, and have one thread read packets, and then dispatch those packets to worker threads. Likewise, another shared resource is the table of TCP control blocks (TCB).
In the real world, Intel network cards solves this problem for you. The network card itself pre-processes TCP packet and hashes the IP/port info. Based on that info, it dispatches packets into different queues. The popular open-source “single-threaded” Snort application exploits this, running a wholly separate process for each queue. Thus, the entire application is “multi-core” even though it’s “single-threaded”, using the pipeline model with one thread (running inside the network adapter) to split traffic into queues, and then worker processes to process the packets.
What I find fascinating about Snort is that it’s probably a stupid idea to make this classically single-threaded program into a multi-threaded program. You don’t need to share most of the data. When you do need to share data, just create a shared memory-region (using page-tables) that multiple processes can use. Take, for example, my “packet counter” examples above. Each Snort process can open up its packet counters in a shared-memory region (using the memory-mapping/page-table feature of the operating system). This would allow another process to read all the packet counters of the individual processors and sum them together, and report the combined packet counters of all the processes.
In other words, a redesigned multi-threaded Snort would put a lot of structures in “thread local storage” anyway. A better design is a multi-process Snort is goes the other direction to move stuff into shared “memory mapped” regions among the process. It’s fundamentally the same thing, especially on Linux where processes/threads are equivalent anyway.
What I’m trying to show you here is that “multi-core” doesn’t automatically mean “multi-threaded”. Snort is single-threaded, but a multi-core product. It doesn’t actually use memory-mapping to share data among processes, and therefore lacks some features, but they probably will in the future.
I mention Snort because it’s also a good example for playing around with Linux features. In theory, Snort can act as an “IPS”, inline with network traffic where good traffic is forwarded and bad traffic is blocked. In practice, this is a bad idea. It’s a bad idea because the Linux kernel switch out a packet processing thread for a few milliseconds, cause enormous jitter problems in Snort. You don’t want this to happen.
The way to fix Snort’s jitter issues is to change the Linux boot parameters. For example, set “maxcpus=2”. This will cause Linux to use only the first two CPUs of the system. Sure, it knows other CPU cores exist, it just will never by default schedule a thread to run on them.
Then what you do in your code is call the “pthread_setaffinity_np()” function call to put your thread on one of the inactive CPUs (there is Snort configuration option to do this per process). As long as you manually put only one thread per CPU, it will NEVER be interrupted by the Linux kernel. Only if you schedule two threads on a CPU will the interruption happen. Thus, you configure each Snort to run on its own dedicates Snort, and a lot of the jitter in IPS mode goes away.
You can still get hardware interrupts, though. Interrupt handlers are really short, so probably won’t exceed your jitter budget, but if they do, you can tweak that as well. Go into “/proc/irq/smp_affinity” and turn of the interrupts in your Snort processing threads.
At this point, I’m a little hazy at what precisely happens. What I think will happen is that your thread won’t be interrupted, not even for a clock cycle. I need to test that using “rdtsc” counters to see exactly when your thread might be interrupted. Even if it is interrupted, it should be good for less than 1-microsecond of jitter. Since an L3 cache miss is 0.1 microseconds of jitter, this is about as low as you can practically get.
Of course, the moment you use a “pthread_mutex_t” in your code for synchronization, then you will get a context switch, and this will throw your entire jitter budget out the window, even if you have scheduled CPUs correctly.
Conclusion
The overall theme of my talk was to impress upon the audience that in order to create scalable application, you need to move your code out of the operating system kernel. You need to code everything yourself instead of letting the kernel do the heavy lifting for you. What I’ve shown in this post is how this applies to thread synchronization. Your basic design should be one thread per core and lock-free synchronization that never causes a thread to stop and wait.
Specifically, I’ve tried to drill into you the idea that what people call “multi-threaded” coding is not the same as “multi-core”. Multi-threaded techniques, like mutexes, don’t scale on multi-core. Conversely, as Snort demonstrates, you can split a problem across multiple processes instead of threads, and still have multi-core code.

